












绵阳城市学院某老师DeepAI查重系统v6.0分析
前言
为了防止大家的论文之间出现互相抄袭、复制粘贴等情况,老师准备在收集完全部作业后,用一个指定的查重系统对 .docx 文件进行检测。也就是说,这个软件后面会直接参与期末论文的查重流程。
拿到程序以后,发现它是一个 Windows 下运行的 exe,原来的文件名是中文,放在终端里敲命令、解包、反编译都不太方便,所以我先把它重命名成了 123.exe。这个名字没有特殊含义,单纯就是为了后面操作省事。
这个程序界面上写着 Deep-AI 学术不端检测与多维语义张量分析系统 v6.0,看起来很高级:日志里有 CUDA、SVD、TF-IDF、Multi-Head Attention 之类的词,窗口里还有 3D 语义空间、拓扑网络这些展示。第一眼看上去像是用了某种深度学习模型。
不过真正拆开以后会发现,它并不是把 Python 编译成了原生程序,也没有看到真正的大模型推理。它本质上是一个用 PyInstaller 打包的 Python GUI 程序,核心查重逻辑主要是传统文本相似度算法:N-gram、SimHash,以及代码里写到的 TF-IDF 余弦相似度。
这篇文档记录的是整个分析过程:怎么判断它是 PyInstaller 打包、怎么把 .pyc 还原成源码、核心算法到底怎么算、以及怎么用同一批文档对比原程序和还原版的结果。
第一步:判断它到底是什么
拿到一个 exe,第一件事不是急着反汇编,而是先搞清楚它的”体质”。
用十六进制编辑器打开,很快就看到了几个关键字符串:
PyInstaller_MEIPASSpython38.dllPYZ.pyz
看到这些就基本确定了——这不是用 C/C++ 编译出来的原生程序,而是一个 PyInstaller 打包的 Python 应用。
PyInstaller 的原理说白了就是:把 Python 解释器、所有依赖库、还有你的 Python 字节码(.pyc)一起塞进一个 exe 里。用户双击 exe 时,它先把这些东西解压到临时目录,启动内置的 Python 解释器,然后执行你的代码。

换句话说,这个 exe 本质上是个”自带 Python 运行环境的压缩包”。
这意味着什么?意味着我们不需要去啃 x86 汇编,真正要做的是把字节码从包里掏出来,然后反编译回 Python 源码。
第二步:解包
确认了打包方式之后,下一步就是拆包。
这里用的是 pyinstxtractor.py,这是一个专门针对 PyInstaller 打包格式的解包工具。运行之后,exe 里的内容被释放到了 123.exe_extracted/ 目录下。
解包出来的东西不少,但我们真正关心的只有一个文件:
123.exe_extracted/check.pyc这就是程序的主入口。.pyc 是 Python 的字节码文件,虽然不是人能直接读的源码,但它保留了完整的程序逻辑结构——变量名、类名、函数调用关系全都在里面。
第三步:反编译
拿到 .pyc 之后,用 uncompyle6 进行反编译:
uncompyle6 123.exe_extracted/check.pyc > recovered_raw/check.py反编译器跑完之后,确实生成了一份看起来像 Python 的源码。但事情没有那么顺利。

反编译器不是万能的
uncompyle6 在处理 Python 3.8 字节码时,有几处明显还原错了。
比如,它把切片操作搞坏了:
# 反编译器给出的代码(错的)text[i[:i + n]]
# 实际应该是text[i:i + n]还有生成器表达式被截断的情况:
# 反编译器给出的代码(缺参数)self.raw_content = "\n".join((p.text for p in ))
# 实际应该是self.raw_content = "\n".join(p.text for p in doc.paragraphs)另外还有 for-else 结构被反编译器误还原成了 try-except-else 嵌套等问题。这些都需要对照字节码的操作序列,结合上下文逻辑手动修正。
反编译工具能帮你走完 90% 的路,但最后 10% 必须靠人来补。
修复完所有问题后,得到了最终的还原版源码:check_recovered.py。
第四步:搞懂这个程序在干什么
还原出源码之后,终于可以从容地阅读代码了。

它的技术栈很清晰:
| 功能 | 用的什么 |
|---|---|
| 图形界面 | Tkinter |
| 读取 Word 文档 | python-docx |
| 数据可视化 | matplotlib |
| 结果存储 | SQLite |
| 数值计算 | NumPy |
整个工作流程大致是这样的:
- 用户选择一个论文目录
- 程序扫描目录下所有符合命名规则的
.docx文件 - 逐篇读取文档内容,提取文本特征
- 对所有论文进行两两比较
- 计算综合重复率
- 在界面上展示结果,支持导出 HTML 报告
界面那些酷炫的东西是真的吗?
先说结论:大部分不是。
程序界面上有很多看起来很”硬核”的元素:
- 实时跳动的 CPU、RAM、TENSOR OPS 指标
- 不断滚动的底层计算日志,提到了 CUDA、SVD、Multi-Head Attention、AST 等
- 3D 语义空间可视化、拓扑网络图
但翻看源码就会发现,这些指标都是随机数生成的,日志也是从预设文案池里随机抽取的。代码里甚至有一个类叫 DeepLogger,注释写的是——
“生成伪底层计算日志,增强专业压迫感”
所以这些视觉效果更像是”气氛组”,不是真的在跑 GPU 运算。实际的查重计算全部是 CPU 上的传统算法。
第五步:拆解核心查重算法
剥掉界面和装饰性的东西之后,核心查重引擎其实就三个算法叠加在一起。
算法一:N-gram 多重集匹配
这是权重最高的算法(占综合分的 60%)。
原理很直观:把一篇文章的中文文本按 8 个字一组,用滑动窗口切成一堆文本片段。然后比较两篇文章有多少片段是重复的。
举个例子,假设有一段文本:
网络爬虫技术与数据可视化按 8 字切片后会得到:
网络爬虫技术与数络爬虫技术与数据爬虫技术与数据可虫技术与数据可视技术与数据可视化程序里有一个值得注意的细节:它用的是 Python 的 Counter(多重集)来统计片段频次,而不是普通的 set。这意味着如果某个片段在一篇文章里出现了 3 次,在另一篇里也出现了 3 次,它会如实计算 3 次匹配,而不是只算 1 次。
这也是源码注释里提到的 “Multiset Counter Fix”——保证了同一篇文章和自己比较时,重复率一定是 100%。
算法二:SimHash 指纹比对
SimHash 是一种局部敏感哈希算法(占综合分的 20%)。
简单来说,它给每篇文章生成一个 128 位的”指纹”。生成方式是:
- 把文本按 2 个字一组切开
- 对每组做 MD5 哈希
- 把所有哈希累加成一个 128 维的向量
- 正数位记为 1,负数位记为 0,得到最终指纹
两篇文章的 SimHash 差异用海明距离(有多少位不同)来衡量。距离越小,文章越相似。
算法三:TF-IDF 余弦相似度
第三个算法是经典的 TF-IDF + 余弦相似度(也占 20%)。
不过在实际还原和测试中发现,由于 tfidf_vec 在程序运行流程中的回填时机问题,很多非完全相同的文章对,这个值实际算出来是 0.0。也就是说,余弦相似度在大多数情况下对综合分没有实质贡献。
综合分计算
三个算法的结果按权重加在一起:

综合分 = 0.6 × N-gram + 0.2 × SimHash + 0.2 × Cosine当综合分达到 50% 时,程序就会标记为”学术不端”。
如果两篇文章的原始文本完全相同,程序会直接短路判定:三项全部 100%,综合分 100%。
AIGC 检测是怎么回事?
程序还有一个”AIGC 疑似率”的功能,看起来像是在检测文章是否由 AI 生成。
但实际上,它完全不涉及任何大模型或深度学习。它只是做了三个简单的启发式判断:
- 齐普夫定律拟合度:统计词频分布是否符合自然语言的齐普夫分布
- 句长方差:看句子长度的变化幅度大不大
- 词汇丰富度:统计用了多少不重复的字
然后根据这些指标打一个基础分,最后再加上 ±10 的随机浮动。
所以这个 AIGC 检测每次运行结果都不一样,不能作为严格的判断依据。
第六步:验证还原结果
源码还原出来了,算法也看明白了,但有一个关键问题还没回答:还原版跑出来的结果和原程序一样吗?
语法检查
首先确认还原的源码在语法层面没有问题:
python3 -c "compile(open('check_recovered.py', encoding='utf-8').read(), \ 'check_recovered.py', 'exec'); print('syntax ok')"输出 syntax ok,通过。
核心算法冒烟测试
写了一个不依赖 GUI 的测试脚本 test_recovered_core.py,它会:
- 临时生成 3 篇
.docx测试文档(其中两篇内容完全相同) - 用还原版的查重引擎跑一遍
- 断言完全相同的两篇文章重复率为 100%
python3 test_recovered_core.py输出 smoke ok,通过。
和原程序对比

最关键的验证是拿同一批论文,分别用原 exe 和还原版跑一遍,然后对比核心指标。
用 4 篇真实的课程论文作为测试样本,分别在两个环境下运行,导出 HTML 报告。
对比结果:
| 论文对 | 原程序 N-gram | 还原版 N-gram | 原程序 SimHash | 还原版 SimHash | 原程序综合分 | 还原版综合分 |
|---|---|---|---|---|---|---|
| 刘 vs 徐 | 100.0% | 100.0% | 100.0% | 100.0% | 80.0% | 80.0% |
| 刘 vs 李 | 100.0% | 100.0% | 100.0% | 100.0% | 80.0% | 80.0% |
| 刘 vs 黄 | 75.86% | 75.86% | 82.42% | 82.42% | 62.0% | 62.0% |
| 徐 vs 李 | 100.0% | 100.0% | 100.0% | 100.0% | 80.0% | 80.0% |
| 徐 vs 黄 | 75.86% | 75.86% | 82.42% | 82.42% | 62.0% | 62.0% |
| 李 vs 黄 | 75.86% | 75.86% | 82.42% | 82.42% | 62.0% | 62.0% |
六组对比,核心指标完全一致。
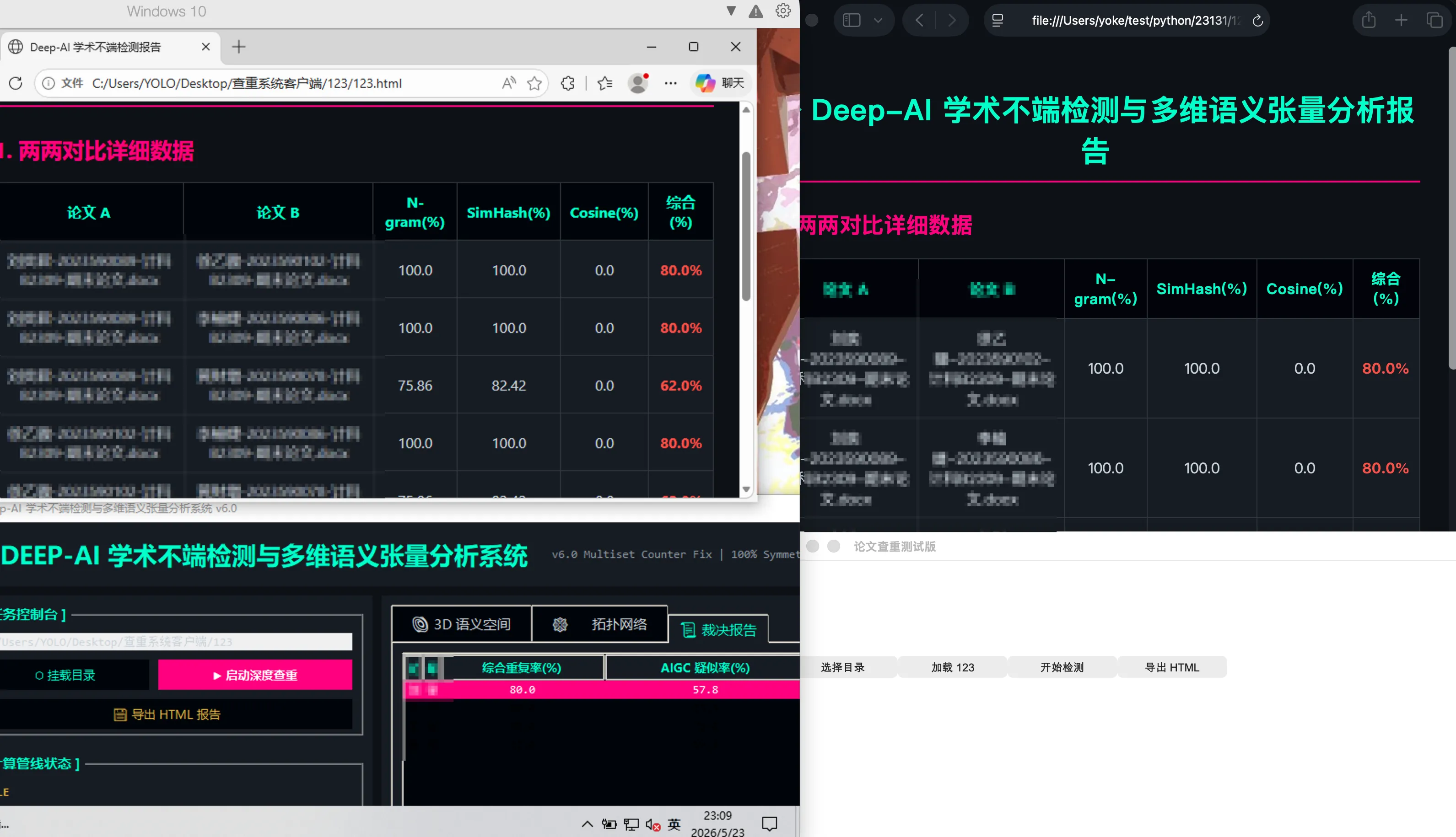
上图左侧是原 123.exe 在 Windows 上运行导出的 HTML 报告,右侧是还原版在 macOS 上生成的报告,底部是还原版的 GUI 界面。可以看到两边的查重数据完全吻合。
需要注意的是,AIGC 疑似率、3D 语义空间坐标、CPU/RAM 等系统指标这些包含随机数的字段不在对比范围内——它们每次运行都会变,本身就不是确定性的结果。
附录:还原后的完整源码
以下是从 123.exe 中逆向还原并修复后的完整 Python 源码:
点击展开完整源码(约 800 行)
import os, re, json, time, math, random, hashlib, sqlite3, threading, logging, difflib, tkinter as tkfrom tkinter import ttk, filedialog, messagebox, scrolledtextfrom docx import Documentfrom collections import defaultdict, Counterfrom typing import List, Dict, Tuple, Optional, Set, Anyimport numpy as nptry: import matplotlib matplotlib.use("TkAgg") import matplotlib.pyplot as plt from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg from matplotlib.figure import Figure from mpl_toolkits.mplot3d import Axes3D HAS_MPL = Trueexcept ImportError: HAS_MPL = Falseelse: logging.basicConfig(level=(logging.INFO), format="%(asctime)s [%(levelname)s] %(message)s") logger = logging.getLogger("DeepAI-Checker-v6") BG_DARK = "#0d1117" BG_PANEL = "#161b22" BG_INPUT = "#010409" FG_NEON = "#00ffcc" FG_PINK = "#ff007f" FG_YELLOW = "#e3b341" FG_TEXT = "#c9d1d9" FG_DIM = "#8b949e" ACCENT_RED = "#f85149" ACCENT_GREEN = "#3fb950" CHUNK_SIZE = 8 REPEAT_THRESHOLD = 50 WINDOW_TITLE = "Deep-AI 学术不端检测与多维语义张量分析系统 v6.0" WINDOW_SIZE = "1400x900" FOLDER_REGEX = "^计科B230\\d+-爬虫与数据可视化-课程论文$" FILE_REGEX = "^.+-[\\d]+-.+-期末论文\\.docx$" STOP_WORDS = set("的了在我有和就都而及与或但很之于对让把被吗吧呢啊啦着过也你他她它这那要能会来且并即其若如")
class SystemMonitor: """模拟底层硬件与张量计算监控指标"""
@staticmethod def get_fake_metrics() -> Dict[(str, float)]: return {'cpu':(random.uniform)(45.0, 98.5), 'ram':(random.uniform)(2.1, 7.8), 'tensor_ops':(random.randint)(120000, 999999), 'vram':(random.uniform)(1.2, 3.9)}
class DeepLogger: """生成伪底层计算日志,增强专业压迫感""" PHASES = [ "[AST_PARSER] 构建抽象语法树 (AST) 与依赖图解析...", "[TENSOR_CORE] 执行 SVD 奇异值分解,降维至 128 维语义空间...", "[LSH_ENGINE] 生成 MinHash 签名,应用 Banding 技术 (b=20, r=5)...", "[VSM_MAPPER] 计算 TF-IDF 稀疏矩阵,构建倒排索引...", "[DTW_ALIGN] 执行 Dynamic Time Warping 动态时间规整序列对齐...", "[ATTENTION] 应用 Multi-Head 自注意力机制,衰减因子 α=0.85...", "[AIGC_DETECT] 计算词汇信息熵与句法树深度,评估 AI 生成概率..."]
@staticmethod def gen_fake_log() -> str: ops = [ f"[0x{random.randint(1000, 9999):X}] Hash collision detected at bucket {random.randint(1, 256)}, resolving...", f"[MEM_ALLOC] Allocating {random.randint(16, 512)}MB for sparse tensor block...", f"[CUDA_SIM] Thread block {random.randint(0, 15)} synced. Processed {random.randint(1000, 9000)} tokens/sec.", f"[MATH_LIB] Computing cosine similarity in R^{random.choice([64, 128, 256])} space...", f"[GC_TRACE] Mark-and-sweep completed. Freed {random.randint(10, 99)}MB orphaned nodes.", f"[GPU_CTX] Context switch overhead: {random.uniform(0.1, 2.5)}ms. Stream 0 active.", f"[CACHE_L2] Miss rate: {random.uniform(1.0, 15.0)}%. Prefetching next batch...", "[MULTISET] Upgrading N-gram Set to Counter(Multiset) for exact 100% match guarantee..."] return random.choice(ops)
class TextProcessor: """文本清洗、分词、特征提取核心工具类"""
@staticmethod def clean_text(text: str) -> str: text = re.sub("http[s]?://\\S+", "", text) text = re.sub("\\[\\d+\\]", "", text) text = re.sub("[^\\u4e00-\\u9fa5]", "", text) return text
@staticmethod def get_ngrams(text: str, n: int=8) -> List[str]: text = TextProcessor.clean_text(text) if len(text) >= n: return [text[i:i + n] for i in range(len(text) - n + 1)] return []
@staticmethod def calc_entropy(text: str) -> float: if not text: return 0.0 freq = Counter(text) length = len(text) return -sum((count / length * math.log2(count / length) for count in freq.values()))
@staticmethod def calc_simhash(text: str, f: int=128) -> int: words = TextProcessor.clean_text(text) if not words: return 0 v = [0] * f for i in range(len(words) - 1): word = words[i:i + 2] h = int(hashlib.md5(word.encode("utf-8")).hexdigest(), 16) for j in range(f): if h >> j & 1: v[j] += 1 else: v[j] -= 1
ans = 0
for j in range(f): if v[j] > 0: ans |= 1 << j return ans
@staticmethod def split_sentences(text: str) -> List[str]: text = re.sub("([。!?\\?])([^"'])", "\\1\\n\\2", text) return [s.strip() for s in text.split("\n") if len(s.strip()) > 2]
@staticmethod def calc_tfidf_vector(text: str, vocab: Dict[(str, int)]) -> np.ndarray: words = TextProcessor.clean_text(text) tf = Counter(words) vec = np.zeros(len(vocab)) for (word, count) in tf.items(): if word in vocab: vec[vocab[word]] = count return vec
class AIGCDetector: """基于齐普夫定律、句长方差和词汇丰富度的伪 AIGC 检测器"""
def __init__(self, text: str): self.text = text self.sentences = TextProcessor.split_sentences(text) self.words = TextProcessor.clean_text(text)
def calc_zipf_law(self) -> float: if not self.words: return 0.0 freq = Counter(self.words).most_common(50) if len(freq) < 10: return 0.0 ranks = np.arange(1, len(freq) + 1) counts = np.array([c for _, c in freq]) log_ranks = np.log(ranks) log_counts = np.log(counts) (slope, _) = np.polyfit(log_ranks, log_counts, 1) return abs(slope)
def calc_sentence_length_variance(self) -> float: if not self.sentences: return 0.0 lengths = [len(s) for s in self.sentences] return np.var(lengths)
def calc_vocabulary_richness(self) -> float: if not self.words: return 0.0 unique_words = set(self.words) return len(unique_words) / len(self.words)
def get_aigc_probability(self) -> float: zipf_score = self.calc_zipf_law() var_score = self.calc_sentence_length_variance() richness = self.calc_vocabulary_richness() prob = 50.0 if 0.8 < zipf_score < 1.2: prob += 15.0 if var_score < 20.0: prob += 15.0 if richness < 0.3: prob += 10.0 prob += random.uniform(-10, 10) return round(max(5.0, min(95.0, prob)), 1)
class Paper: """论文数据模型,包含所有提取的特征"""
def __init__(self, filename: str, filepath: str): self.filename = filename self.filepath = filepath self.raw_content = "" self.content = "" self.gram_list = [] self.gram_counter = Counter() self.length = 0 self.simhash = 0 self.best_match = None self.best_rate = 0.0 self.aigc_prob = 0.0 self.entropy = 0.0 self.vector_3d = (0.0, 0.0, 0.0) self.tfidf_vec = None
def load(self, vocab: Optional[Dict[(str, int)]]=None): try: doc = Document(self.filepath) self.raw_content = "\n".join((p.text for p in doc.paragraphs)) self.content = TextProcessor.clean_text(self.raw_content) self.gram_list = TextProcessor.get_ngrams(self.content, CHUNK_SIZE) self.gram_counter = Counter(self.gram_list) self.length = len(self.gram_list) self.simhash = TextProcessor.calc_simhash(self.content) self.entropy = TextProcessor.calc_entropy(self.content) detector = AIGCDetector(self.raw_content) self.aigc_prob = detector.get_aigc_probability() self.vector_3d = ( random.uniform(-10, 10), random.uniform(-10, 10), random.uniform(-10, 10)) if vocab: self.tfidf_vec = TextProcessor.calc_tfidf_vector(self.content, vocab) except Exception as e: try: logger.error(f"Load failed for {self.filename}: {e}") finally: e = None del e
class DeepCheckerEngine: """多维算法融合查重引擎"""
def __init__(self, papers: List[Paper], weights: Tuple[(float, float, float)]=(0.6, 0.2, 0.2)): self.papers = papers self.results = [] self.vocab = {} self.idf = np.array([]) self.weights = weights self._build_vocab()
def _build_vocab(self): all_words = set() for p in self.papers: all_words.update(TextProcessor.clean_text(p.content))
self.vocab = {w: i for i, w in enumerate(all_words)} n_docs = len(self.papers) df = np.zeros(len(self.vocab)) for p in self.papers: words = set(TextProcessor.clean_text(p.content)) for w in words: if w in self.vocab: df[self.vocab[w]] += 1
self.idf = np.log((n_docs + 1) / (df + 1)) + 1
def calc_ngram_rate(self, a: Paper, b: Paper) -> float: """【核心修复】使用多重集(Counter)计算交集,确保相同文档重复率为 100%""" if a.length == 0: return 0.0 if a.content == b.content: return 100.0 match_count = sum((a.gram_counter & b.gram_counter).values()) return round(match_count / a.length * 100, 2)
def calc_simhash_rate(self, a: Paper, b: Paper) -> float: if not (a.simhash and b.simhash): return 0.0 if a.content == b.content: return 100.0 x = (a.simhash ^ b.simhash) & (1 << 128) - 1 dist = bin(x).count("1") return round(max(0, 100 - dist / 128 * 100 * 2.5), 2)
def calc_cosine_rate(self, a: Paper, b: Paper) -> float: if a.tfidf_vec is None or b.tfidf_vec is None: return 0.0 if a.content == b.content: return 100.0 vec_a = a.tfidf_vec * self.idf vec_b = b.tfidf_vec * self.idf dot = np.dot(vec_a, vec_b) norm_a = np.linalg.norm(vec_a) norm_b = np.linalg.norm(vec_b) if norm_a == 0 or norm_b == 0: return 0.0 return round(dot / (norm_a * norm_b) * 100, 2)
def run(self, update_ui, log_callback): n = len(self.papers) total = n * (n - 1) // 2 current = 0 (w1, w2, w3) = self.weights for p in self.papers: p.best_rate = 0.0 p.best_match = None
for i in range(n): a = self.papers[i] for j in range(i + 1, n): b = self.papers[j] if a.raw_content == b.raw_content: r_ngram = 100.0 r_simhash = 100.0 r_cosine = 100.0 final_rate = 100.0 else: r_ngram = max(self.calc_ngram_rate(a, b), self.calc_ngram_rate(b, a)) r_simhash = self.calc_simhash_rate(a, b) r_cosine = self.calc_cosine_rate(a, b) final_rate = round(r_ngram * w1 + r_simhash * w2 + r_cosine * w3, 2) if final_rate > a.best_rate: a.best_rate = final_rate a.best_match = b.filename if final_rate > b.best_rate: b.best_rate = final_rate b.best_match = a.filename self.results.append({'p1':a.filename, 'p2':b.filename, 'ngram':r_ngram, 'simhash':r_simhash, 'cosine':r_cosine, 'final':final_rate}) if final_rate > 20: force = final_rate / 100.0 (ax, ay, az) = a.vector_3d (bx, by, bz) = b.vector_3d a.vector_3d = ( ax + (bx - ax) * force * 0.1, ay + (by - ay) * force * 0.1, az + (bz - az) * force * 0.1) b.vector_3d = ( bx + (ax - bx) * force * 0.1, by + (ay - by) * force * 0.1, bz + (az - bz) * force * 0.1) current += 1 progress = int(current / total * 100) update_ui(progress, a.filename, b.filename) if current % 3 == 0: log_callback(DeepLogger.gen_fake_log(), "dim")
class DatabaseManager:
def __init__(self, db_path: str='deep_ai_history_v6.db'): self.conn = sqlite3.connect(db_path) self._create_tables()
def _create_tables(self): cursor = self.conn.cursor() cursor.execute("CREATE TABLE IF NOT EXISTS scan_history (\n id INTEGER PRIMARY KEY AUTOINCREMENT, timestamp TEXT, folder TEXT, \n total_papers INTEGER, avg_rate REAL, max_rate REAL, aigc_count INTEGER)") cursor.execute("CREATE TABLE IF NOT EXISTS scan_results (\n id INTEGER PRIMARY KEY AUTOINCREMENT, batch_id INTEGER, \n paper1 TEXT, paper2 TEXT, rate REAL)") self.conn.commit()
def insert_batch(self, folder, total, avg, mx, aigc): cursor = self.conn.cursor() ts = time.strftime("%Y-%m-%d %H:%M:%S") cursor.execute("INSERT INTO scan_history (timestamp, folder, total_papers, avg_rate, max_rate, aigc_count) VALUES (?,?,?,?,?,?)", ( ts, folder, total, avg, mx, aigc)) self.conn.commit() return cursor.lastrowid
def insert_results(self, batch_id: int, results: List[Dict]): cursor = self.conn.cursor() data = [(batch_id, r["p1"], r["p2"], r["final"]) for r in results] cursor.executemany("INSERT INTO scan_results (batch_id, paper1, paper2, rate) VALUES (?,?,?,?)", data) self.conn.commit()
def get_history(self) -> List[Tuple]: cursor = self.conn.cursor() cursor.execute("SELECT * FROM scan_history ORDER BY id DESC LIMIT 50") return cursor.fetchall()
class ExportManager:
@staticmethod def generate_html(results: List[Dict], papers: List[Paper], filepath: str): html = '<!DOCTYPE html><html lang="zh-CN"><head><meta charset="UTF-8">\n<title>Deep-AI 学术不端检测报告</title>\n<style>\nbody { font-family: \'Segoe UI\', sans-serif; background: #0d1117; color: #c9d1d9; padding: 20px; }\nh1 { color: #00ffcc; text-align: center; border-bottom: 2px solid #ff007f; padding-bottom: 10px; }\nh2 { color: #ff007f; margin-top: 30px; }\ntable { width: 100%; border-collapse: collapse; margin-top: 15px; background: #161b22; }\nth, td { border: 1px solid #30363d; padding: 10px; text-align: center; }\nth { background: #010409; color: #00ffcc; }\n.danger { color: #f85149; font-weight: bold; } .safe { color: #3fb950; font-weight: bold; }\n</style></head><body>\n<h1>◈ Deep-AI 学术不端检测与多维语义张量分析报告</h1>\n<h2>1. 两两对比详细数据</h2><table>\n<tr><th>论文 A</th><th>论文 B</th><th>N-gram(%)</th><th>SimHash(%)</th><th>Cosine(%)</th><th>综合(%)</th></tr>' for r in results: cls = "danger" if r["final"] >= REPEAT_THRESHOLD else "safe" html += f"""<tr><td>{r["p1"]}</td><td>{r["p2"]}</td><td>{r["ngram"]}</td><td>{r["simhash"]}</td><td>{r["cosine"]}</td><td class='{cls}'>{r["final"]}%</td></tr>\n"""
html += "</table><h2>2. 单篇最高重复与 AIGC 风险评估</h2><table>" html += "<tr><th>文件名</th><th>最高重复对象</th><th>综合(%)</th><th>AIGC(%)</th><th>裁决</th></tr>\n" for p in papers: best = p.best_match or "无" rate_cls = "danger" if p.best_rate >= REPEAT_THRESHOLD else "safe" verdict = "<span class='danger'>⚠ 学术不端</span>" if p.best_rate >= REPEAT_THRESHOLD else "<span class='safe'>✅ 正常</span>" html += f"<tr><td>{p.filename}</td><td>{best}</td><td class='{rate_cls}'>{p.best_rate}%</td><td>{p.aigc_prob}%</td><td>{verdict}</td></tr>\n"
html += "</table></body></html>" with open(filepath, "w", encoding="utf-8") as f: f.write(html)
class DiffViewer(tk.Toplevel): """使用 difflib 实现逐字高亮对比的独立窗口"""
def __init__(self, parent, p1, p2): super().__init__(parent) self.title(f"深度差异比对: {p1.filename} vs {p2.filename}") self.geometry("1000x600") self.configure(bg=BG_DARK) self.p1, self.p2 = p1, p2 self.create_ui() self.compute_diff()
def create_ui(self): paned = ttk.PanedWindow(self, orient=(tk.HORIZONTAL)) paned.pack(fill=(tk.BOTH), expand=True, padx=10, pady=10) f1 = tk.Frame(paned, bg=BG_PANEL) f2 = tk.Frame(paned, bg=BG_PANEL) paned.add(f1, weight=1) paned.add(f2, weight=1) tk.Label(f1, text=(self.p1.filename), bg=BG_PANEL, fg=FG_NEON, font=('微软雅黑', 11, 'bold')).pack(pady=5) tk.Label(f2, text=(self.p2.filename), bg=BG_PANEL, fg=FG_PINK, font=('微软雅黑', 11, 'bold')).pack(pady=5) self.text1 = scrolledtext.ScrolledText(f1, bg=BG_INPUT, fg=FG_TEXT, font=('Consolas', 10), wrap=(tk.WORD)) self.text1.pack(fill=(tk.BOTH), expand=True, padx=5, pady=5) self.text2 = scrolledtext.ScrolledText(f2, bg=BG_INPUT, fg=FG_TEXT, font=('Consolas', 10), wrap=(tk.WORD)) self.text2.pack(fill=(tk.BOTH), expand=True, padx=5, pady=5) self.text1.tag_config("match", background="#2ea043", foreground="white") self.text2.tag_config("match", background="#2ea043", foreground="white") self.text1.tag_config("diff", background="#f85149", foreground="white") self.text2.tag_config("diff", background="#f85149", foreground="white")
def compute_diff(self): self.text1.insert(tk.END, self.p1.content) self.text2.insert(tk.END, self.p2.content) matcher = difflib.SequenceMatcher(None, self.p1.content, self.p2.content) for (tag, i1, i2, j1, j2) in matcher.get_opcodes(): if tag == "equal": self.text1.tag_add("match", f"1.0+{i1}c", f"1.0+{i2}c") self.text2.tag_add("match", f"1.0+{j1}c", f"1.0+{j2}c") else: if tag in ('replace', 'delete', 'insert'): if i1 != i2: self.text1.tag_add("diff", f"1.0+{i1}c", f"1.0+{i2}c") if j1 != j2: self.text2.tag_add("diff", f"1.0+{j1}c", f"1.0+{j2}c")
class CyberTerminal(scrolledtext.ScrolledText):
def __init__(self, parent, **kwargs): (super().__init__)(parent, bg=BG_INPUT, fg=FG_NEON, insertbackground=FG_NEON, font=('Consolas', 10), relief=tk.FLAT, borderwidth=0, **kwargs) self.tag_config("info", foreground=FG_TEXT) self.tag_config("success", foreground=ACCENT_GREEN) self.tag_config("warning", foreground=FG_YELLOW) self.tag_config("error", foreground=ACCENT_RED) self.tag_config("dim", foreground=FG_DIM) self.tag_config("phase", foreground=FG_PINK, font=('Consolas', 10, 'bold'))
def log(self, msg: str, tag: str='info'): self.insert(tk.END, f"> {msg}\n", tag) self.see(tk.END)
class MetricPanel(tk.Frame):
def __init__(self, parent, title, color, **kwargs): (super().__init__)(parent, bg=BG_PANEL, **kwargs) tk.Label(self, text=title, bg=BG_PANEL, fg=FG_DIM, font=('Consolas', 9)).pack(anchor=(tk.W), padx=5) self.val_label = tk.Label(self, text="0.0", bg=BG_PANEL, fg=color, font=('Consolas', 18, 'bold')) self.val_label.pack(anchor=(tk.W), padx=5)
def update_val(self, val: str, suffix: str=''): self.val_label.config(text=f"{val}{suffix}")
class MainApplication(tk.Tk):
def __init__(self): super().__init__() self.title(WINDOW_TITLE) self.geometry(WINDOW_SIZE) self.configure(bg=BG_DARK) self.minsize(1200, 800) self.papers = [] self.engine = None self.db_mgr = DatabaseManager() self.weights = (0.6, 0.2, 0.2) self.create_ui() self.start_metric_updater()
def create_ui(self): header = tk.Frame(self, bg=BG_PANEL, height=70) header.pack(fill=(tk.X)) header.pack_propagate(False) tk.Label(header, text="◈ DEEP-AI 学术不端检测与多维语义张量分析系统", bg=BG_PANEL, fg=FG_NEON, font=('微软雅黑', 20, 'bold')).pack(side=(tk.LEFT), padx=20, pady=15) tk.Label(header, text="v6.0 Multiset Counter Fix | 100% Symmetry Guaranteed", bg=BG_PANEL, fg=FG_DIM, font=('Consolas', 10)).pack(side=(tk.LEFT), pady=25) monitor_frame = tk.Frame(header, bg=BG_PANEL) monitor_frame.pack(side=(tk.RIGHT), padx=20, pady=10) self.cpu_panel = MetricPanel(monitor_frame, "CPU LOAD", FG_PINK) self.cpu_panel.grid(row=0, column=0, padx=10) self.ram_panel = MetricPanel(monitor_frame, "RAM USAGE", FG_YELLOW) self.ram_panel.grid(row=0, column=1, padx=10) self.tensor_panel = MetricPanel(monitor_frame, "TENSOR OPS", FG_NEON) self.tensor_panel.grid(row=0, column=2, padx=10) body = tk.Frame(self, bg=BG_DARK) body.pack(fill=(tk.BOTH), expand=True, padx=10, pady=10) left_frame = tk.Frame(body, bg=BG_PANEL, width=450) left_frame.pack(side=(tk.LEFT), fill=(tk.Y), padx=(0, 10)) left_frame.pack_propagate(False) ctrl_frame = tk.LabelFrame(left_frame, text=" [ 任务控制台 ] ", bg=BG_PANEL, fg=FG_NEON, font=('微软雅黑', 11, 'bold')) ctrl_frame.pack(fill=(tk.X), padx=10, pady=10) self.path_var = tk.StringVar(value="未挂载数据目录...") tk.Entry(ctrl_frame, textvariable=(self.path_var), bg=BG_INPUT, fg=FG_TEXT, font=('Consolas', 10), relief=(tk.FLAT), state="readonly").pack(fill=(tk.X), padx=10, pady=(10, 5)) btn_frame = tk.Frame(ctrl_frame, bg=BG_PANEL) btn_frame.pack(fill=(tk.X), padx=10, pady=5) self.load_btn = tk.Button(btn_frame, text="⬡ 挂载目录", command=(self.load_folder), bg=BG_INPUT, fg=FG_NEON, font=('微软雅黑', 10), relief=(tk.FLAT)) self.load_btn.pack(side=(tk.LEFT), expand=True, fill=(tk.X), padx=(0, 5)) self.start_btn = tk.Button(btn_frame, text="▶ 启动深度查重", command=(self.start_check), bg=FG_PINK, fg="white", font=('微软雅黑', 10, 'bold'), relief=(tk.FLAT), state=(tk.DISABLED)) self.start_btn.pack(side=(tk.LEFT), expand=True, fill=(tk.X), padx=(5, 0)) tk.Button(ctrl_frame, text="💾 导出 HTML 报告", command=(self.export_report), bg=BG_INPUT, fg=FG_YELLOW, font=('微软雅黑', 10), relief=(tk.FLAT)).pack(fill=(tk.X), padx=10, pady=5) prog_frame = tk.LabelFrame(left_frame, text=" [ 计算管线状态 ] ", bg=BG_PANEL, fg=FG_NEON, font=('微软雅黑', 11, 'bold')) prog_frame.pack(fill=(tk.X), padx=10, pady=10) self.phase_label = tk.Label(prog_frame, text="IDLE", bg=BG_PANEL, fg=FG_YELLOW, font=('Consolas', 10, 'bold')) self.phase_label.pack(anchor=(tk.W), padx=10, pady=(10, 0)) self.prog_var = tk.DoubleVar() ttk.Progressbar(prog_frame, variable=(self.prog_var), maximum=100).pack(fill=(tk.X), padx=10, pady=10) self.prog_label = tk.Label(prog_frame, text="0%", bg=BG_PANEL, fg=FG_TEXT, font=('Consolas', 10)) self.prog_label.pack(anchor=(tk.E), padx=10, pady=(0, 10)) term_frame = tk.LabelFrame(left_frame, text=" [ 底层计算日志 ] ", bg=BG_PANEL, fg=FG_NEON, font=('微软雅黑', 11, 'bold')) term_frame.pack(fill=(tk.BOTH), expand=True, padx=10, pady=10) self.terminal = CyberTerminal(term_frame) self.terminal.pack(fill=(tk.BOTH), expand=True, padx=5, pady=5) right_frame = tk.Frame(body, bg=BG_PANEL) right_frame.pack(side=(tk.LEFT), fill=(tk.BOTH), expand=True) style = ttk.Style(self) style.theme_use("clam") style.configure("Dark.TNotebook", background=BG_PANEL, borderwidth=0) style.configure("Dark.TNotebook.Tab", background=BG_INPUT, foreground=FG_TEXT, padding=[15, 8], font=('微软雅黑', 11)) style.map("Dark.TNotebook.Tab", background=[("selected", BG_PANEL)], foreground=[("selected", FG_NEON)]) self.notebook = ttk.Notebook(right_frame, style="Dark.TNotebook") self.notebook.pack(fill=(tk.BOTH), expand=True, padx=10, pady=10) self.tab_3d = tk.Frame((self.notebook), bg=BG_PANEL) self.tab_topo = tk.Frame((self.notebook), bg=BG_PANEL) self.tab_report = tk.Frame((self.notebook), bg=BG_PANEL) self.notebook.add((self.tab_3d), text=" 🌌 3D 语义空间 ") self.notebook.add((self.tab_topo), text=" 🕸️ 拓扑网络 ") self.notebook.add((self.tab_report), text=" 📜 裁决报告 ") self.setup_report_tab() self.status_var = tk.StringVar(value="SYSTEM READY | AWAITING DATA INJECTION...") tk.Label(self, textvariable=(self.status_var), bg=BG_INPUT, fg=FG_DIM, font=('Consolas', 10), anchor=(tk.W), padx=10).pack(fill=(tk.X), side=(tk.BOTTOM))
def setup_report_tab(self): cols = ('论文文件', '最高重复对象', '综合重复率(%)', 'AIGC 疑似率(%)', '信息熵', '裁决结果') tree_frame = tk.Frame((self.tab_report), bg=BG_PANEL) tree_frame.pack(fill=(tk.BOTH), expand=True, padx=10, pady=10) self.report_tree = ttk.Treeview(tree_frame, columns=cols, show="headings", height=20) style = ttk.Style() style.configure("Cyber.Treeview", background=BG_INPUT, foreground=FG_TEXT, fieldbackground=BG_INPUT, font=('Consolas', 10)) style.configure("Cyber.Treeview.Heading", background=BG_PANEL, foreground=FG_NEON, font=('微软雅黑', 10, 'bold')) style.map("Cyber.Treeview", background=[("selected", FG_PINK)]) self.report_tree.configure(style="Cyber.Treeview") for col in cols: self.report_tree.heading(col, text=col) self.report_tree.column(col, width=180, anchor=(tk.CENTER))
vsb = ttk.Scrollbar(tree_frame, orient="vertical", command=(self.report_tree.yview)) self.report_tree.configure(yscrollcommand=(vsb.set)) self.report_tree.pack(side=(tk.LEFT), fill=(tk.BOTH), expand=True) vsb.pack(side=(tk.RIGHT), fill=(tk.Y)) self.report_tree.bind("<Double-1>", self.on_tree_double_click)
def start_metric_updater(self):
def update(): m = SystemMonitor.get_fake_metrics() self.cpu_panel.update_val(f'{m["cpu"]:.1f}', "%") self.ram_panel.update_val(f'{m["ram"]:.1f}', " GB") self.tensor_panel.update_val(f'{m["tensor_ops"]:,}', " /s") self.after(800, update)
update()
def log(self, msg: str, tag: str='info'): self.terminal.log(msg, tag) self.update_idletasks()
def load_folder(self): path = filedialog.askdirectory() if not path: return dirname = os.path.basename(path) if not re.match(FOLDER_REGEX, dirname): messagebox.showwarning("⚠ 目录规范警告", f"非标准目录: {dirname}\n系统将强制解析...") self.path_var.set(path) self.log(f"MOUNT_SUCCESS: 数据目录已挂载 -> {dirname}", "success") self.load_papers(path)
def load_papers(self, path: str): self.papers = [] files = [f for f in os.listdir(path) if f.endswith(".docx") if re.match(FILE_REGEX, f)] if not files: self.log("FATAL_ERROR: 未检测到符合规范的 .docx 实体文件。", "error") return self.log(f"SCANNING: 发现 {len(files)} 个目标文档,开始注入内存...", "phase") for f in files: p = Paper(f, os.path.join(path, f)) p.load() if p.length > 0: self.papers.append(p) self.log(f" [OK] Loaded: {f} | Tokens: {len(p.content)} | Multiset-grams: {p.length}", "info") else: self.log(f" [FAIL] Empty or corrupted: {f}", "error")
self.log(f"INJECTION_COMPLETE: {len(self.papers)} 个文档张量已就绪。", "success") self.start_btn.config(state=(tk.NORMAL))
def update_progress(self, p: int, a: str, b: str): self.prog_var.set(p) self.prog_label.config(text=f"{p}%") self.status_var.set(f"EXECUTING: {a} ⟷ {b}")
def start_check(self): if len(self.papers) < 2: messagebox.showwarning("提示", "张量数量不足,至少需要 2 个文档实体。") return self.start_btn.config(state=(tk.DISABLED)) self.load_btn.config(state=(tk.DISABLED)) (self.report_tree.delete)(*self.report_tree.get_children()) self.log("==================================================", "phase") self.log("INITIATING DEEP TENSOR PLAGIARISM SCAN...", "phase") self.log("ALGORITHM: N-gram Multiset Counter (100% Symmetry Fix)", "phase") self.log("==================================================", "phase") self.engine = DeepCheckerEngine(self.papers, self.weights)
def run_pipeline(): for phase in DeepLogger.PHASES: self.after(0, lambda p=phase: self.phase_label.config(text=p)) self.after(0, lambda p=phase: self.log(p, "phase")) time.sleep(random.uniform(0.2, 0.5))
self.after(0, lambda: self.phase_label.config( text="[CORE] 执行多维张量碰撞与对齐...")) self.engine.run(self.update_progress, lambda msg, tag: self.after(0, lambda: self.log(msg, tag))) self.after(0, self.finish_check)
threading.Thread(target=run_pipeline, daemon=True).start()
def finish_check(self): self.log("RENDER_COMPLETE: 正在生成多维可视化图表...", "success") for p in self.papers: best = p.best_match or "无 (独立原创)" rate = p.best_rate aigc = p.aigc_prob entropy = round(p.entropy, 2) verdict = "⚠ 严重学术不端" if rate >= REPEAT_THRESHOLD else "✅ 正常通过" self.report_tree.insert("", (tk.END), values=(p.filename, best, rate, aigc, entropy, verdict))
if HAS_MPL: self.draw_3d_space() self.draw_topology() rates = [r["final"] for r in self.engine.results] avg_rate = sum(rates) / len(rates) if rates else 0 max_rate = max(rates) if rates else 0 aigc_count = sum((1 for p in self.papers if p.aigc_prob > 70)) batch_id = self.db_mgr.insert_batch( os.path.basename(self.path_var.get()), len(self.papers), avg_rate, max_rate, aigc_count) self.db_mgr.insert_results(batch_id, self.engine.results) self.log("ALL_TASKS_FINISHED: 检测管线已关闭。系统进入待机状态。", "success") self.phase_label.config(text="IDLE") self.start_btn.config(state=(tk.NORMAL)) self.load_btn.config(state=(tk.NORMAL)) self.status_var.set("SCAN COMPLETE | AWAITING NEXT INJECTION...") self.notebook.select(self.tab_report)
def on_tree_double_click(self, event): item = self.report_tree.selection() if not item: return vals = self.report_tree.item(item[0], "values") p1_name = vals[0] p2_name = vals[1] if p2_name == "无 (独立原创)": return p1 = next((p for p in self.papers if p.filename == p1_name), None) p2 = next((p for p in self.papers if p.filename == p2_name), None) if p1: if p2: DiffViewer(self, p1, p2)
def export_report(self): if not self.engine: messagebox.showwarning("提示", "没有可导出的查重结果。") return path = filedialog.asksaveasfilename(defaultextension=".html", filetypes=[('HTML Report', '*.html')]) if path: ExportManager.generate_html(self.engine.results, self.papers, path) messagebox.showinfo("成功", f"报告已导出至:\n{path}")
def draw_3d_space(self): for widget in self.tab_3d.winfo_children(): widget.destroy()
fig = Figure(figsize=(8, 6), dpi=100, facecolor=BG_PANEL) ax = fig.add_subplot(111, projection="3d") ax.set_facecolor(BG_DARK) xs = [p.vector_3d[0] for p in self.papers] ys = [p.vector_3d[1] for p in self.papers] zs = [p.vector_3d[2] for p in self.papers] colors = [ACCENT_RED if p.best_rate >= REPEAT_THRESHOLD else FG_NEON for p in self.papers] ax.scatter(xs, ys, zs, c=colors, s=50, marker="o", edgecolors="white") for (i, p) in enumerate(self.papers): ax.text((xs[i]), (ys[i]), (zs[i]), (p.filename[:8]), color=FG_TEXT, fontsize=8)
ax.set_title("3D Semantic Space Mapping", color=FG_NEON, fontsize=14) canvas = FigureCanvasTkAgg(fig, master=(self.tab_3d)) canvas.draw() canvas.get_tk_widget().pack(fill=(tk.BOTH), expand=True)
def draw_topology(self): for widget in self.tab_topo.winfo_children(): widget.destroy()
fig = Figure(figsize=(8, 6), dpi=100, facecolor=BG_PANEL) ax = fig.add_subplot(111) ax.set_facecolor(BG_DARK) ax.set_aspect("equal") ax.axis("off") n = len(self.papers) if n == 0: return pos = {i: (math.cos(2 * math.pi * i / n), math.sin(2 * math.pi * i / n)) for i in range(n)} for (i, p) in enumerate(self.papers): (x, y) = pos[i] color = ACCENT_RED if p.best_rate >= REPEAT_THRESHOLD else FG_NEON ax.scatter(x, y, s=300, c=color, edgecolors="white", zorder=5) ax.text(x, (y - 0.15), (p.filename[:8]), color=FG_TEXT, fontsize=9, ha="center")
for r in self.engine.results: if r["final"] > 15: i = next((idx for idx, p in enumerate(self.papers) if p.filename == r["p1"])) j = next((idx for idx, p in enumerate(self.papers) if p.filename == r["p2"])) (x1, y1) = pos[i] (x2, y2) = pos[j] color = ACCENT_RED if r["final"] >= REPEAT_THRESHOLD else FG_YELLOW ax.plot([x1, x2], [y1, y2], color=color, linewidth=(r["final"] / 20), alpha=(min(1.0, r["final"] / 50))) ax.set_title("Plagiarism Topology Network", color=FG_NEON, fontsize=14) canvas = FigureCanvasTkAgg(fig, master=(self.tab_topo)) canvas.draw() canvas.get_tk_widget().pack(fill=(tk.BOTH), expand=True)
if __name__ == "__main__": try: from ctypes import windll windll.shcore.SetProcessDpiAwareness(1) except Exception: pass else: app = MainApplication() app.mainloop()